A cartoon guide to Facebook’s Relay, part 2

GraphQL gives you a way to say what part of a graph you need, as you saw in part 1.
Relay makes the connection between the graph in the cloud and the graph that the user is interacting with on the page.
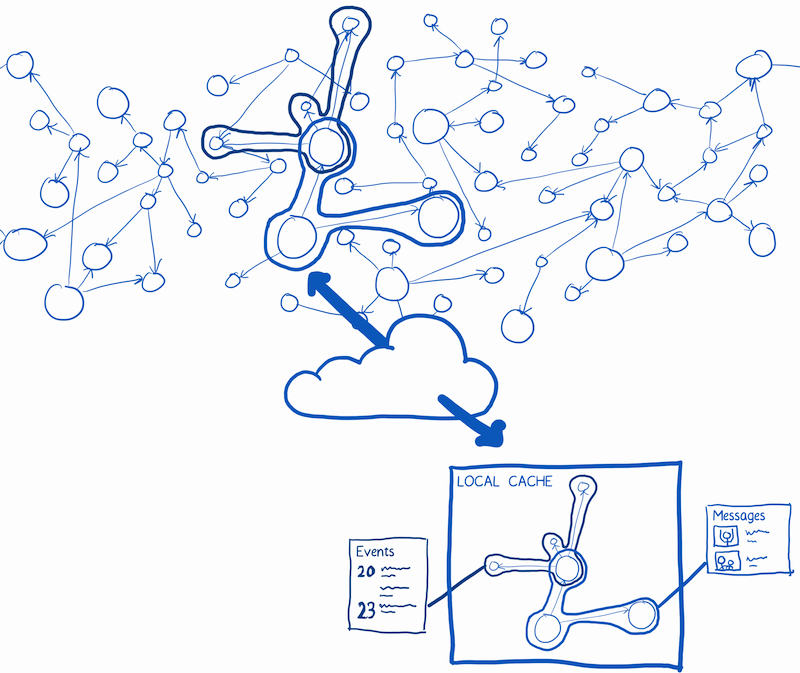
Relay can automate:
- downloading the bits of the graph that you need and caching them
- making future requests for data smaller
- figuring out which parts of the graph you really need right now, and which you can wait for
It also automates syncing any changes to the graph back up to the server. We’ll cover this in part 3.
Downloading and caching
The UI doesn’t talk to the server directly. Instead, it gets all of the data from the store, which has a local cache of the data.
When the page loads initially, the UI will ask the store to prime the cache. This will pull down the data from the server. Then the UI can do it’s first render.

- First, the system needs to figure out what data to get from the server. It gathers all of the query fragments from the components that will be shown. Then, it stitches those together into a single graph. That graph query is requested from the server.
- The server responds by filling in the part of the graph described by the query with the actual data. The data is added to the local cache.
- The UI gets a notification that the data is ready and in the cache (more about this below). The UI asks the store for the data and renders it.
Making queries smaller
Now we have data in the cache. Because of this, Relay can make future queries smaller.

- The system figures out what parts of the query it already has and what parts it needs.
- The part that is already cached is removed from the query. Then the reduced graph query is sent to the server.
- The little bit of the graph that was missing is returned from the server. The store merges it into the local cache. The UI is notified that the data is in, and it asks the store for the data.
Deferring queries
Sometimes, you have two kinds of data needs. Some data needs to be fetched immediately to render the page, and other data that can come in later.
For example, on a news article the article body needs to be rendered immediately. But comments, which aren’t really that important, can be rendered a few seconds later.
In theory, Relay makes it possible to split up the queries. When the required data comes in, the page will render. When the deferred data comes in, it will be added to the page.

- The query graph is split up based on whether the properties are deferred. The deferred query is marked as dependent on the required query.
- The server responds with the required data. The UI renders the page with that data.
- The server responds with the deferred data. The UI updates the page with the data.
Note: While Relay itself can handle deferred queries, there is a piece of the puzzle missing. Facebook’s GraphQL server can handle dependencies between queries, but for simplicity’s sake they didn’t add it to the GraphQL spec. They do plan to make it possible though, and you can follow the issue.
To do these things, Relay introduces a new character — the query system.
Introducing the query system
The query system is in charge of figuring out what data to fetch. It works together with the store to figure out the smallest queries that it can send.

I think of the query system as a bike messenger who’s obsessed with efficiency. Before sending a query, it checks what data is in the store. It won’t ask the server for data the store already has.
It will even go above and beyond to make the query smaller. It checks what data is supposed to come in from pending requests. Instead of sending a concurrent request for the same data, it will just clip away parts that it expects to come in from the pending requests.
How the store and query system team up
The query system is just a small part of Relay. I’ll cover the rest of the characters later. But I think it’s helpful to get a detailed view of how the query system works with the store to automate data fetching, and how the two talk with the server and the UI.
Note: Everything in this cartoon is automatically handled by Relay. So you don’t technically need to know how this works. But it’s more fun when you do!

Here’s an example of the interaction between these two.


1. The UI asks the store to fill up the cache. Specifically, it asks for the data that is needed for the first render.
2. The store delegates this to the query system.

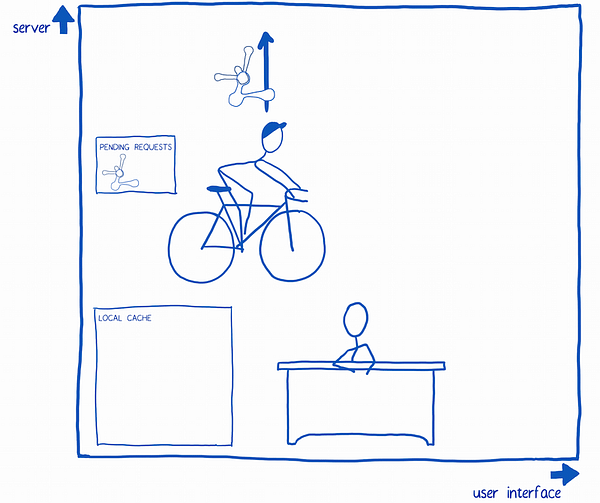
3. The query system tries to make the query as small as possible.
4. The query system sends the query off. It adds it to the list of requests that are pending.
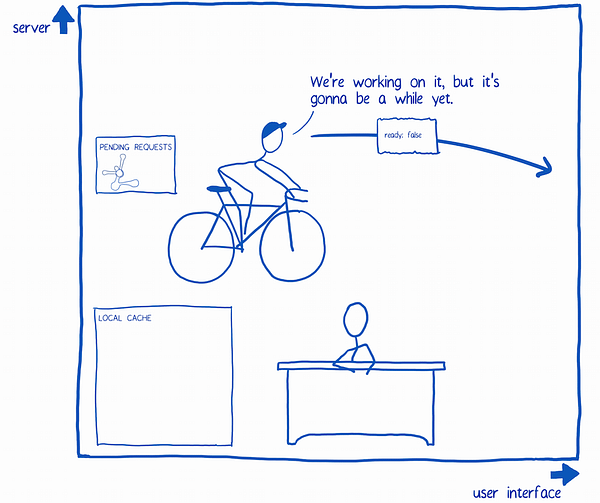
5. In the meantime, the query system wants to let the UI know what’s going on.
It sends a ready state message to the UI (it does this with a callback that the UI passed to the store, and the store passed to it). In the ready state message, the ready property is set to false since the data hasn’t come in yet.
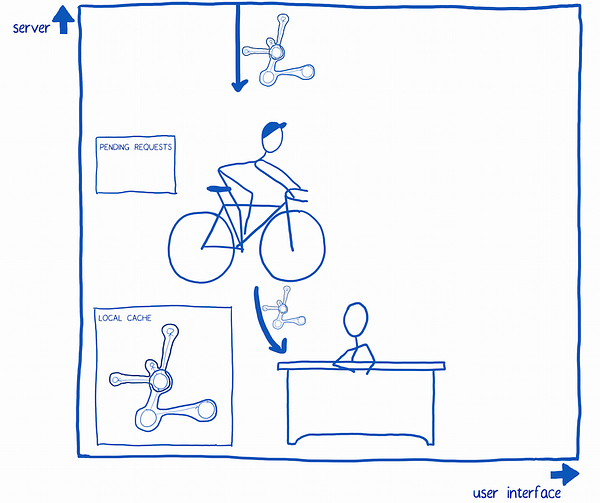
6. When the query results come back, the query system sends them to the store. It also removes the request from the list of pending requests. The store adds the results to the local cache.
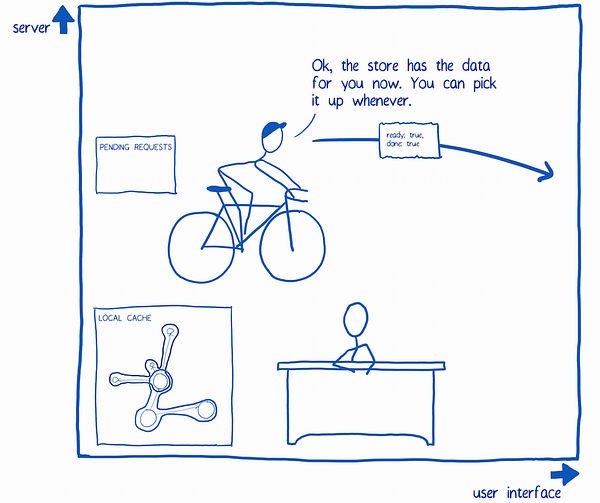

7. The query system lets the UI know that it can get the data from the store.
8. The UI asks the store for the data. The store gives it the data and also sets up some observers. These will be used to target updates to specific components when new data comes in.
So that’s how I think of data fetching in Relay. Hope it helps!
Did this help? If it did, a click on the ♥ is much appreciated… it helps other people find it, too!
Coming up next
Syncing changes back up to the server with Relay.


