A cartoon guide to Facebook’s Relay, part 3

Relay is the same as Flux and Redux in a way. All three of them use objects to represent changes. When a change object comes through to the store, the store will make the change in the state. Then the store will notify the UI to update.
Unlike Flux and Redux, Relay pushes the change up to the server, too.
Sometimes changes aren’t simple, though. They can ripple out and have effects that aren’t so obvious.
For example, take adding new content. It could have impacts on other parts of the graph, too.
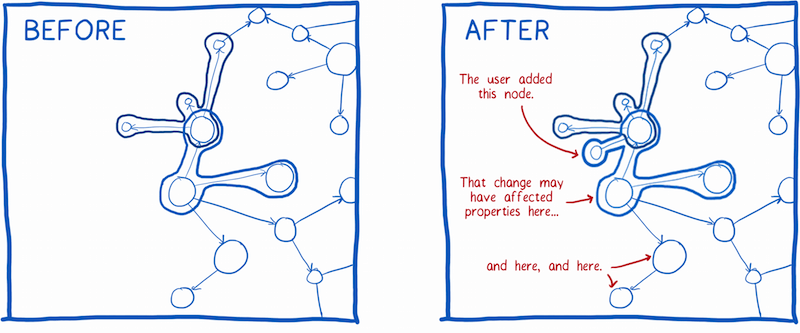
Balancing speed and consistency
How do you 1) show all of the changes, but 2) do it as quickly as possible?
To show all the changes, you could just refetch the whole graph… but that would be slow. Or you could just fetch the one change you made… but then the data isn’t consistent with what’s on the server.
Relay balances these two — speed and consistency. It does that by figuring out exactly what data it needs to update.
It will also make the change seem to happen faster by doing an “optimistic update”. This is where the app guesses what the new state will be before the server responds. When the server response does come in, it will make any necessary changes.
Here’s the sequence of events:
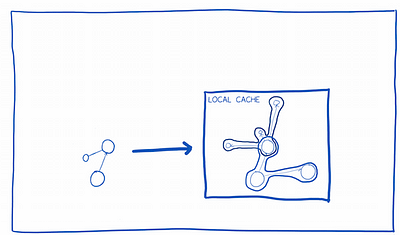
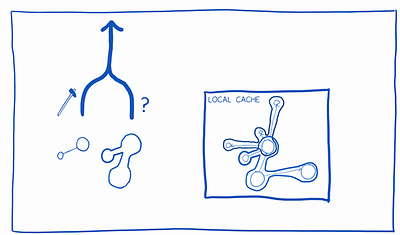
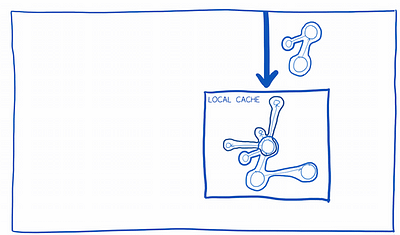
1. Relay updates the local cache with what it thinks the new state is going to be (an “optimistic update”… I’ll explain how it figures this out later).
2. It sends up the mutation query to the server. It also sends a query graph that requests data from the server. Once the server makes the update, it will fill in that query graph and return it as the payload.
3. The store will merge the payload into the graph it already has cached. If the optimistic update in step 1 was incorrect, those changes will be overwritten here.
Relay manages all this by introducing another new system, the mutation system.
Introducing mutations & the mutation system
Mutations are the Relay version of the actions you see in Flux or Redux. Instead of having an action type that comes from a list of constants, the Relay mutation has a name which comes from the list of mutations the server understands.
A mutation object knows its mutation name. And, like an action creator, it knows how to prepare the input… the variables the server will need to make the change.
But it does more than an action creator in Flux or Redux does.
The mutation
I think of the mutation as an architect. It provides a set of blueprints for different things.
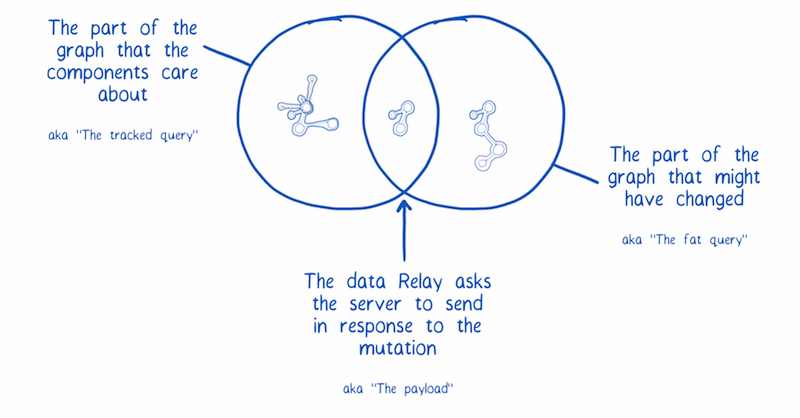
It provides a blueprint for the fat query. This is a list of the fields that might change in response to the mutation. It can also provide a blueprint for optimistic updates.
When data comes back from the server, it provides a blueprint for how the store’s data should change in response to the mutation. The blueprint guides the store in figuring out how to change fields or delete data.
This set of blueprints is handed off to the mutation system.
The mutation system
The mutation system is like a contractor carrying out and directing the work on that set of blueprints.
It takes the blueprint for the fat query and compares it to the graph of data that the app is currently using, called the tracked query. It figures out which data needs to be refreshed. If a property is in both graphs, it gets added to the mutation request.
Note: The mutation defines this fat query, not the component. This means even if a seemingly unrelated component has made a change, if it impacts another component’s data, all of the changed data will still be fetched from the server. This is great because you get consistency without coupling components together.
If the mutation has a blueprint for an optimistic update, it carries that out.
How the store and mutation system team up
Just as the store works with the query system for fetching data, it works with the mutation system for changing data.


1. The UI passes a mutation object to the store.
2. The store passes the mutation to the mutation system.


3. The mutation system figures out what the optimistic update should be. It tells the store to update the cache with that data.
4. The store writes the data and sets up a broadcast to fire later. That broadcast will let the UI know that there is new data to show.


5. The mutation system compares the fat and tracked queries to figure out the smallest bit of data that the server needs to send down. It sends the request, which includes the change to make and the query.
6. The broadcast that the store set up in step 4 goes out. The UI requests the data that the optimistic update changed.


7. The mutation system receives the payload. It passes it to the store, which updates the cache. Then it queues up another broadcast to the UI.
8. The UI gets the new data from the store.
So that’s how I think of mutations and data syncing in Relay. Hope it helps!
Did this help? If it did, a click on the ♥ is much appreciated… it helps other people find it, too!
Coming up next…
See how it all fits together in part 4.